LargeWorldModel defeats all other LLMs just because it's trained differently
LWM finds the needle in the haystack faster and with less processing power
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more
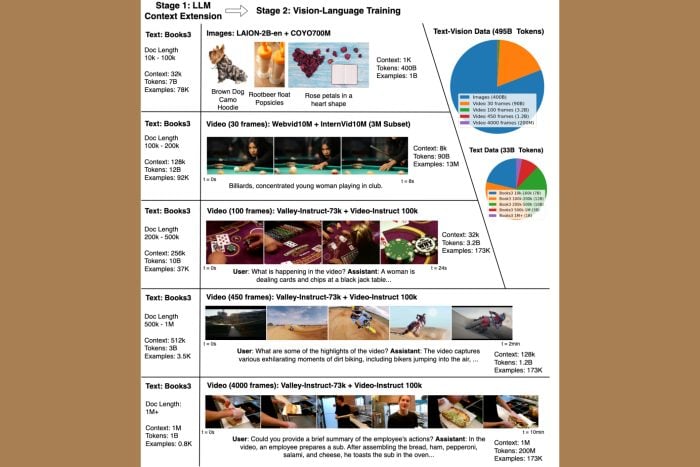
As spotted by ZDNet, the LargeWorldModel (LWM) appeared out of nowhere and demonstrated that it can find the needle in the haystack of a one hour YouTube video faster and using less resources than any other LLM.
LWM is a GitHub project developed by Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel, a team of students from the University of California at Berkeley, which makes it all even more exciting.
What are the LargeWorldModel results?
The students performed the Needle in the Haystack test on their model, which involves feeding the bot a one hour video with more than 500 clips from YouTube and asking it precise questions to identify.

Their LWM outperformed all other LLMs and answered all the questions correctly in less time and using less tokens, which translates into lower computing power needed.
This capability was also demonstrated by Gemini 1.5, although Google’s bot is definitely having some problems right now.
However, to be fair, LWM was tested against Gemini 1.0, not Gemini 1.5 which, according to Google’s technical report, is significantly better.
Another particularity is that the LWM tests were performed for 58 hours on one slice of a TPU Version 4 POD, made out of 256 TPU chips. The Google’s technical report only specifies that they trained their model on TPU Version 4 and Version 5 PODs, so we don’t really know the extent of used resources.
How did they do it?
The students came up with a new training approach called Ring Attention. Instead of feeding the model with sequential sample data, Liu’s team provides the data concurrently, thus avoiding training blocking. That technique leads to less processing time and the training is using the chips more efficiently.
To be more specific, the LWM was trained in multiple successive steps, using larger and larger data samples each round. They started with 32,768 tokens and gradually increased the amount to 1 million.
Intuitively, this allows the model to save compute by first learning shorter-range dependencies before moving onto longer sequences. By doing this, we are able to train on orders of magnitude more tokens compared to directly training on the maximum target sequence length
LWM project technoical description
Google doesn’t provide too much information on how they have trained their model but they say that it can work with an input of up to 10 million tokens. In comparison, according to the Berkeley team, Ring Attention only depends on the number of devices available and theoretically can extend to unlimited content.
There only one thing that the LWM was not addressed: the audio identification and that is also handled by Gemini 1.5.
Considering that the LWM project is open source and available on GitHub, anyone can get the code and develop it further. So, we’re witnessing exciting developments in the AI model training here.
What do you think about the new training model? Let’s discuss it in the comments section below.



User forum
0 messages