Microsoft’s training Small Language Models to outperform ChatGPT

Microsoft may have a $10 billion dollar investment and partnership with OpenAI for its ChatGPT Large Language Model but it looks like the company could be hedging its bets with its own smaller transformer technology.
Microsoft researchers recently revealed its Phi-1 1.3B transformer-based language model beat much larger models including HumanEval, MBPP, and even partnered ChatGPT when tasked with coding.
Combing “textbook quality” from The Stack and The StackOverflow datasets to train the artificial intelligence of Phi-1 1.3B and the use of eight NVIDIA A1000 GPUs over four days produced 6 billion high-quality training tokens based on GPT-4 classifiers and 7 billion generated using GPT 3.5 standards.
Not only did Phi-1 1.3B outperform some of its larger language model counterparts, it did so using fewer parameters.
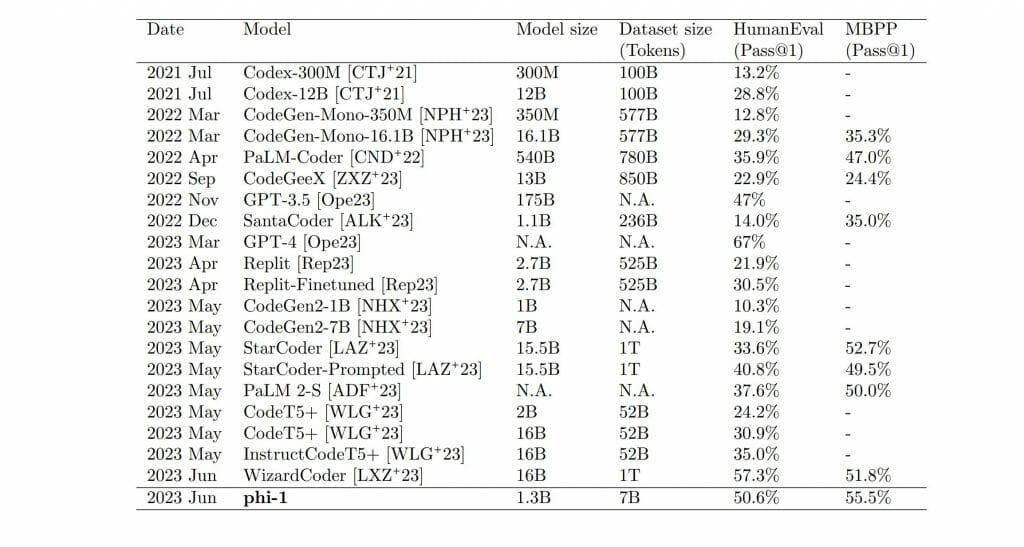
While the researchers may be popping bottles of champagne in excitement, Phi-1 1.3Bs achievements are tempered by its comparative limited versatility. Unlike larger models, Phi-1 1.3B gains ground through its specialized training in Python programming and as such, misses out on specific API programming resulting in less knowledge about domain specifics than larger models tend to have.
At the end of the day, Phi-1 1.3B success highlights the need for higher quality data to flow through these language models to optimize their output.
Microsoft’s other SML Orca has also proven to outperform ChatGPT in similar testing, further lending credence to the necessity for high quality data to shrink the resource question of LLMs.
Microsoft is planning to open-source Phi-1 1.3B through HuggingFace, but as of now, there is no official date for the release.
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more


Improve this guide


User forum
0 messages