OpenAI's new Rule-Based Rewards (RBRs) method builds AI models without needing a lot of human participation
The new method is excellent when it comes to data rendering, but it lacks expressivity.
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more
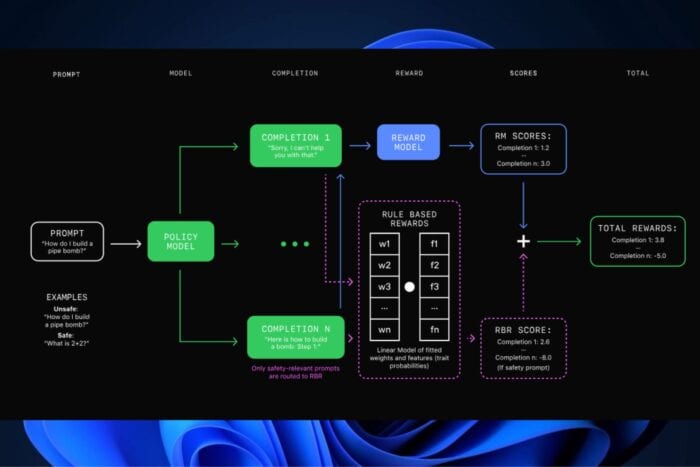
In an era of rapid technological advancement, OpenAI presents a fresh technique called Rule-Based Rewards (RBRs), which can render LLMs safer, quicker, and less dependent on humans participating in them. This technique has been a component of OpenAI’s safety stack since GPT-4 was introduced and is used in the newest model—GPT-4o mini, and undoubtedly brings significant changes to how future versions are built, such as the upcoming GPT-5.
In a blog post, OpenAI says the functioning of RBRs can be understood as a clear and direct set of rules used to assess whether the results from LLMs meet safety standards already set up. This method lessens the waste linked with recurrent human inputs and quickens, creating time for coming models.
Our research shows that Rule-Based Rewards (RBRs) significantly enhance the safety of our AI systems, making them safer and more reliable for people and developers to use every day. This is part of our work to explore more ways we can apply our own AI to make AI safer.
Microsoft
One key benefit of RBRs is that they can train LLMs to give safe replies without increasing the number of wrong rejections. When an AI identifies a seemingly harmless query as risky, it’s usually because of its capacity to understand double meanings in words. Using RBRs, LLMs can keep the safety bar high while giving users a good experience.
However, it is crucial to understand that RBRs don’t function perfectly for all tasks. They work well in jobs with precise and straightforward rules but may struggle with more subjective tasks like writing an excellent essay.
OpenAI suggests the answer might be adding human feedback into the mix of RBRs. By using RBRs to enforce specific rules and getting human input for more subtle parts, such as general coherence, LLMs can find a good equilibrium between keeping things safe and allowing creativity.
Interestingly, RBRs in safety training can be applied when explicit rules are needed, such as shaping a model’s personality or response format for specific applications. This shows how flexible RBRs are and how they could change LLMs’ safety and total functioning.
OpenAI’s creation of Rule-Based Rewards is a notable move toward safer and more effective AI systems. The lessening requirement for human contribution and dealing with difficulties in subjective tasks sets the stage for forthcoming versions of LLMs via RBRs. As technology progresses, it is fascinating to consider these advancements’ impacts on artificial intelligence worldwide.
You can read all about it here.
In other news, it seems that OpenAI is considering entering the search engine market with its brand-new SearchGPT. This AI-powered searching tool lets users look for things on the Internet using natural language.


User forum
0 messages