Microsoft's new Synthetic Data will train AI models as well as personal data
Microsoft researchers managed to create synthetic data that emulates personal data.
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more
In a world where data is worth its weight in gold, there’s an ongoing struggle between utilizing its potential and safeguarding personal privacy. Picture yourself on the front lines of this dispute, attempting to understand how to use data for training AI models while avoiding crossing into privacy violation territory.
Many organizations encounter this challenge, and Microsoft is in a privacy controversy with its new AI-powered Recall; however, synthetic data provides a light at the end of the tunnel. Synthetic data acts like a superhero in the data world, helping construct believable datasets without violating personal privacy.
This implies that firms can continue training their AI models well, follow tough rules on data privacy, and might also be able to utilize new AI applications that were not possible earlier due to a lack of or issues related to data availability and privacy.
Microsoft’s Phi-3 small language model (SLM) illustrates the responsible use of synthetic data. It successfully avoids the requirement for real-world personal information by blending well-made web data with synthetic content created from large language models (LLMs).
But synthetic data also has weaknesses. It can be challenging to create artificial data that is realistic and representative of diverse use cases without introducing bias or inaccuracies.
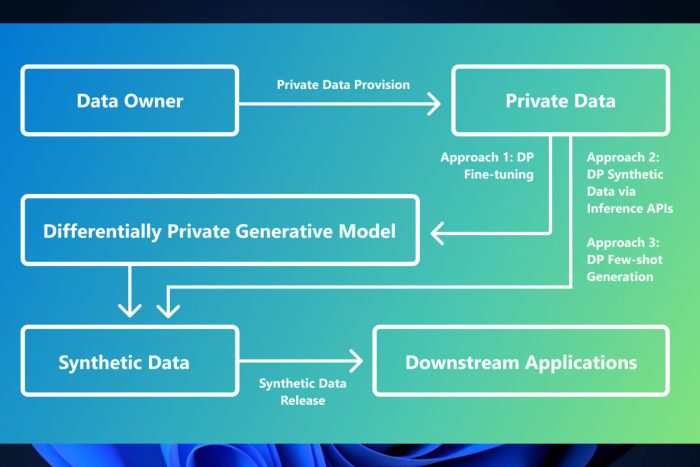
Differential privacy—the name might appear complicated at first, but at its core, it’s about applying a mathematical safeguard to data. This method assures that the created data is similar for practical purposes yet modified adequately so as not to reveal specific identities. It provides an innovative shift by providing a means to create without risking privacy.
Now, we are entering the realm of technical magic. The researchers at Microsoft have been creating ways to make synthetic data with these privacy protections built in. One method is adjusting how we train generative LLMs with differential privacy by introducing some noise during training so it stays anonymous but still realistic.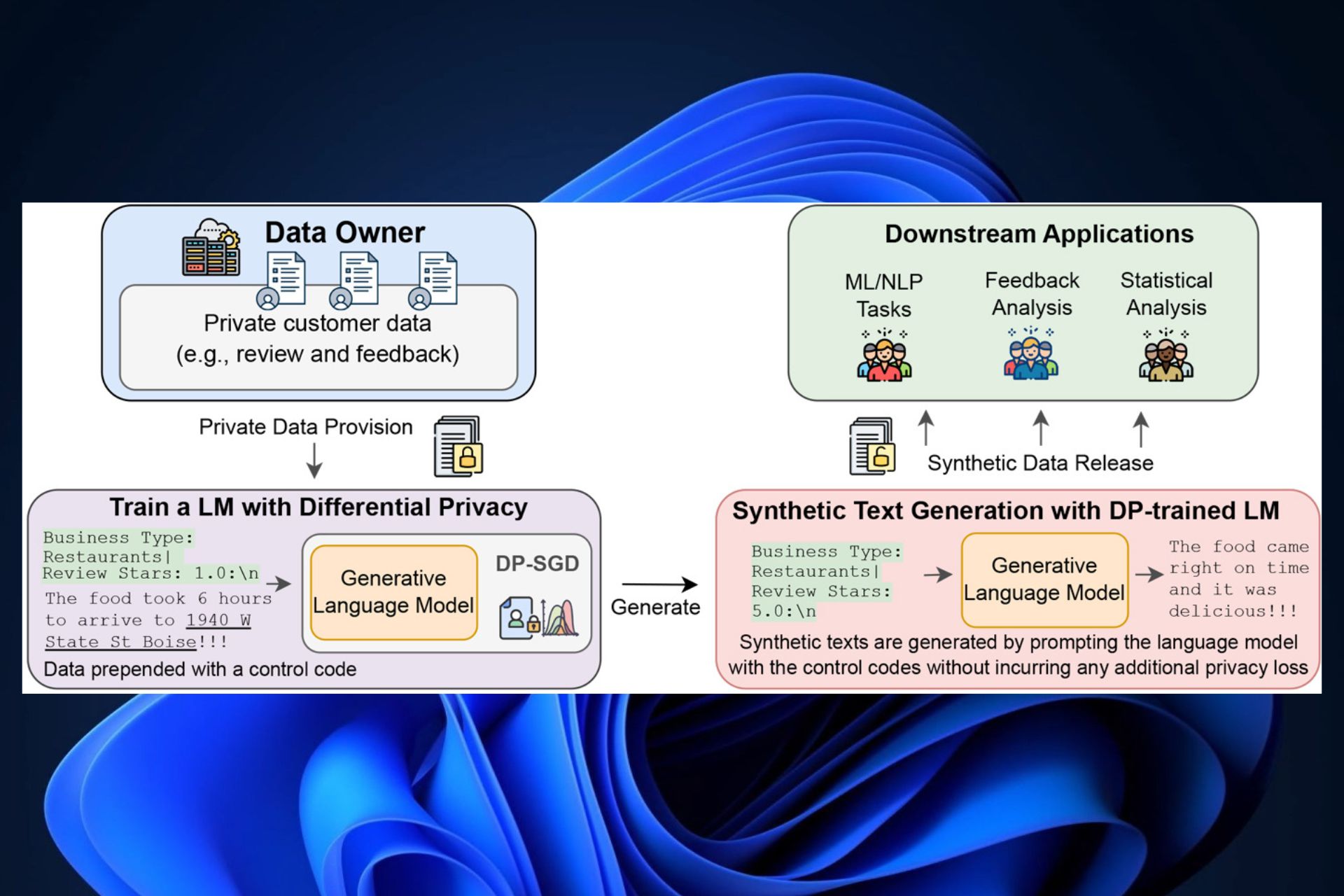
Another creative idea doesn’t need any training. It treats pre-trained models like a black box and involves querying them to generate fresh data in a privacy-protecting manner. This could be useful for people who cannot train big models starting from zero.
But what if you possess only a small number of instances, and they are confidential? The researchers have an answer to this as well. You can create synthetic instances guided by private information but guarded by differential privacy. Therefore, AI models can still learn efficiently without jeopardizing the privacy of those involved.
The path to finding an equilibrium between innovation and privacy keeps progressing. The developments in creating synthetic data hint at a future where AI can advance while protecting our privacy rights.
It’s a delicate balance between algorithms and morals, but it is key for the ongoing development of responsible AI.


User forum
0 messages