VLOGGER AI: Now create a lifelike avatar from a photo & use your voice to control it
And, it looks kind a real
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more
Researchers at Google are working on making its AI technology smarter every day. One of the latest research projects that they are working on is VLOGGER.
VLOGGER is explained as
A method for text and audio driven talking human video generation from a single input image of a person, which builds on the success of recent generative diffusion models.
Our method consists of 1) a stochastic human-to-3d-motion diffusion model, and 2) a novel diffusion based architecture that augments text-to-image models with both temporal and spatial controls.
According to the blog post on GitHub, this approach allows for the generation of high-quality videos of desirable length. Without the need for training for every person, it doesn’t depend on face detection cropping; it can generate the complete image and take a broad spectrum into account, which is important for synthesizing humans who communicate.
As of now, VLOGGER is not available for use as it is still under development, but when it hits the market, it could be a great way to communicate in a video conference on Skype, Teams, or Slack.
Google is quite confident in the project and has tested it through various benchmarks; here is what it says:
We evaluate VLOGGER on three different benchmarks and show that the proposed model surpasses other state-of-the-art methods in image quality, identity preservation and temporal consistency. We collect a new and diverse dataset MENTOR one order of magnitude bigger than previous ones (2,200 hours and 800,000 identities, and a test set of 120 hours and 4,000 identities) on which we train and ablate our main technical contributions. We report the performance of VLOGGER with respect to multiple diversity metrics, showing that our architectural choices benefit training a fair and unbiased model at scale.
How does VLOGGER work?
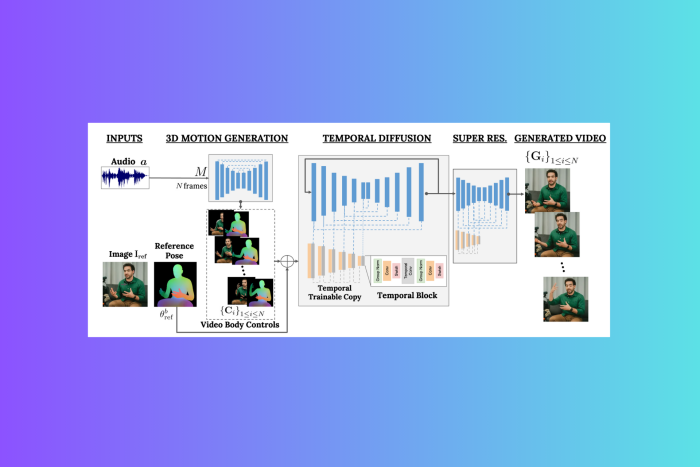
VLOGGER is a framework that acts as a two-stage pipeline and works on stochastic diffusion architecture that powers text to image, video & even 3D models but also adds a control mechanism.
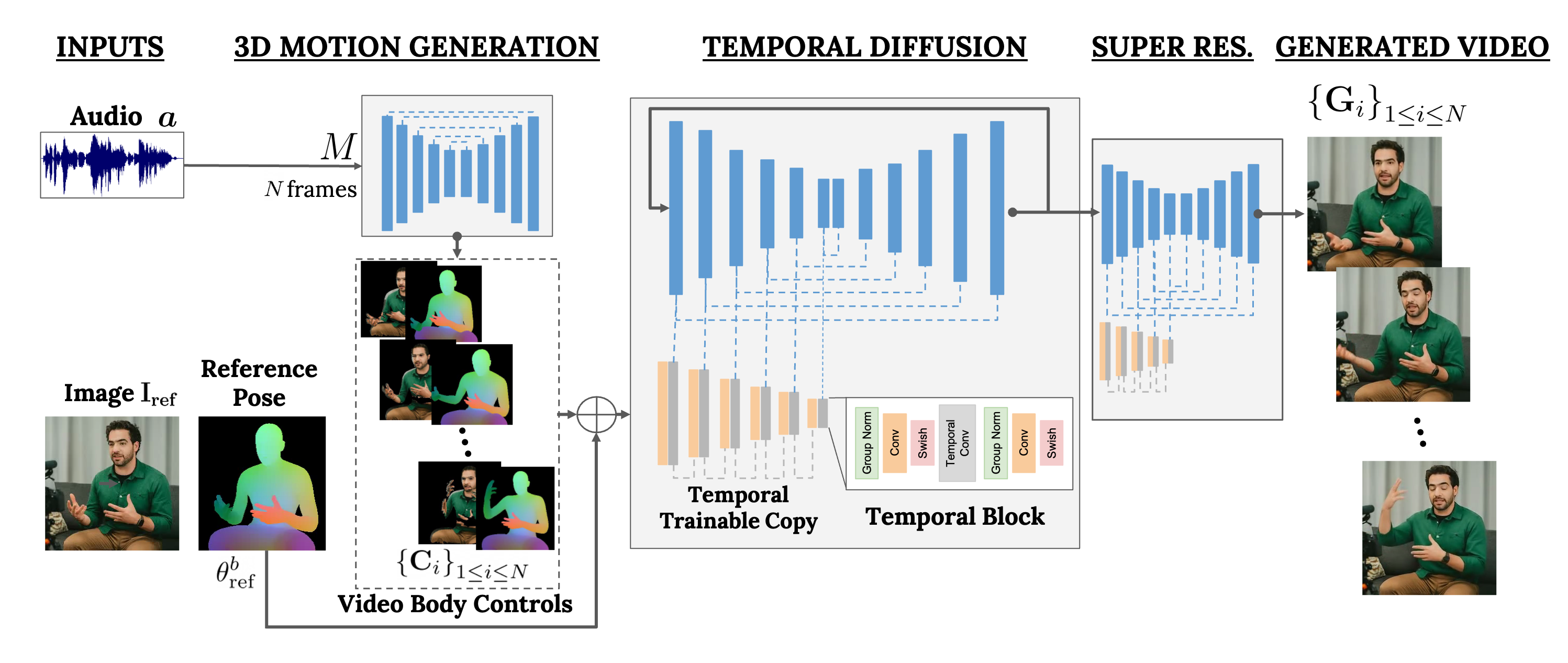
The first step is to take an audio waveform as an input to generate intermediate body motion controls like gaze and facial expressions. Next, the second network uses a temporal image-to-image translation model to identify these movements and a reference image of a person to generate frames for the video.
Another important feature of VLOGGER is the ability to edit existing videos. It can take a video and change the expression of the person in the video.
Furthermore, the VLOGGER can also help in video translation; it can take an existing video in a specific language and edit the lips & face area to make it consistent with new audio or different languages.
As VLOGGER is not a product but a research project and is not complete, it can’t be relied upon. Yes, it can create realistic-like motion, but it may not be able to match how a person really moves. Given its diffusion model, it could show unusual behavior.
Its team also mentioned that it is not versed in large motions or diverse environments and can only work for short videos.
According to the features mentioned on the GitHub page, it can help create talking and moving virtual avatars, chatbots, and more.
Do you think it could be helpful for you? Share your opinions with our readers in the comments section below

User forum
0 messages