AI gets into your browser and it's faster than ever
Now, AI chatbots will work a lot faster in the browsers

We were wondering when will they use the full power of AI within our browsers and, apparently, the time has come.
We’re talking about a new feature called ONNX Runtime Web which uses the WebGPU accelerator that allows AI models to be built directly into the browser and make them faster. A lot faster!
What is the ONNX Runtime Web?
To explain that, you need to know that WebGPU is engine, like WebGL, but a lot more powerful, capable of dealing with larger computational workloads. It is basically harnessing the GPU power to perform parallel computational tasks needed in AI processes.
Now, getting to ONNX Runtime Web, it is a JavaScript library that enables web developers to embed LLMs right into the web browsers and benefit from the GPU hardware acceleration.
Usually, large LLMs are not so easily deployed into browsers because they require a lot of memory and computational power.
ONNX Runtime Web’s innovation is that it enables the WebGPU backend which Microsoft and Intel are developing right now.
How fast is the ONNX Runtime Web?
To prove their point, the ONNX Runtime team created a demo using the Segment Anything model, and the results were little short of amazing.
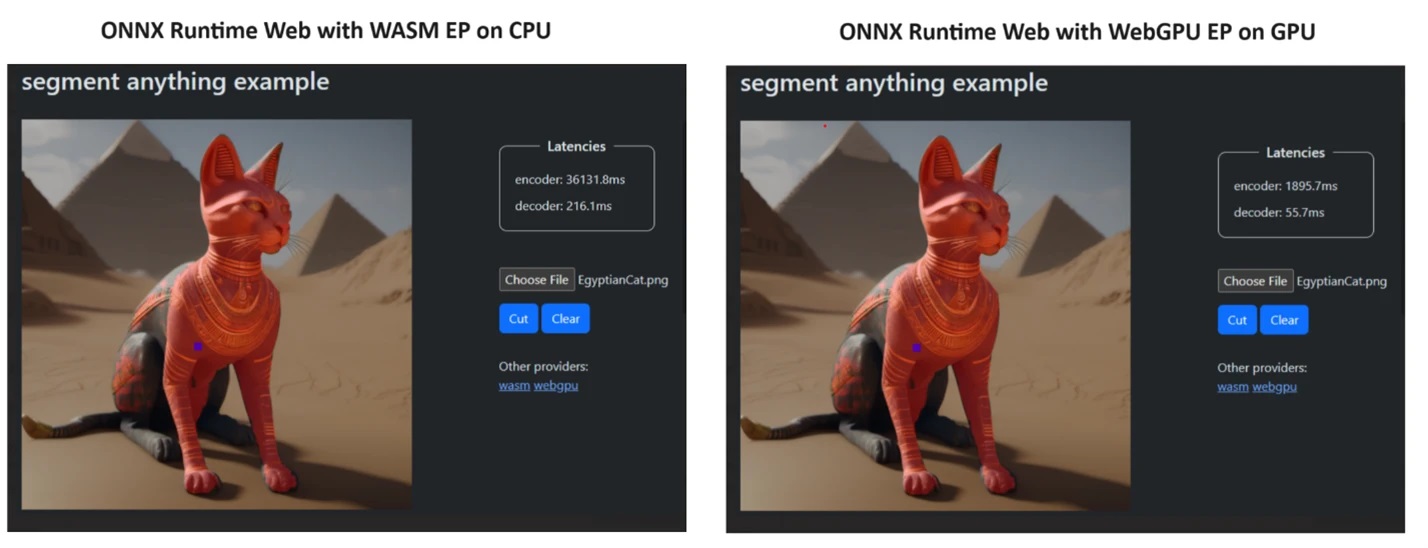
They incorporated WASM EP and WebGPU EP and used an NVIDIA GeForce RTX 3060 and Intel Core i9 PC. Then, they compared the encoder using the CPU and the new WebGPU and the latter proved to be a lot faster, as shown in the screenshot above.
The good news is that WebGPU is already embedded into Chrome 113 and Edge 113 for Windows, macOS and ChromeOS and Chrome 121 for Android. That means you can also play with ONNX Runtime Web on these browsers.
The developers explained how to try ONNX Runtime Web on their project page:
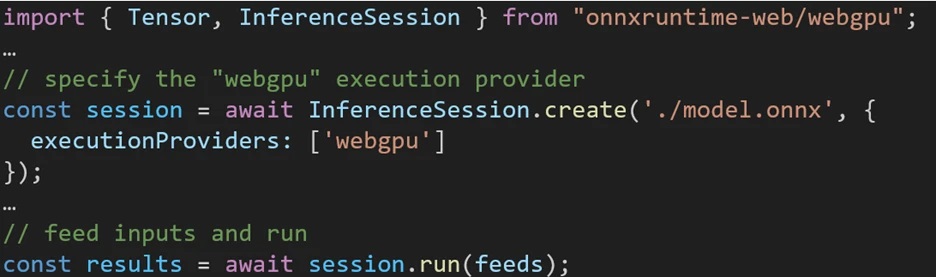
The experience utilizing different backends in ONNX Runtime Web is straightforward. Simply import the relevant package and create an ONNX Runtime Web inference session with the required backend through the Execution Provider setting. We aim to simplify the process for developers, enabling them to harness different hardware accelerations with minimal effort.
The following code snippet shows how to call ONNX Runtime Web API to inference a model with WebGPU. Additional ONNX Runtime Web documentation and examples are accessible for delving deeper.
Microsoft Open Source Blog
So, now that we have anything in place, let’s start deploying some powerful LLMs into the browsers!
What do you think about the new ONNX Runtime Web? Let’s talk about this development in the comments section below.
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more


Improve this guide



User forum
0 messages