Microsoft Brings OpenAI’s "gpt-oss-120b & 20b" Models to Azure and Windows AI Foundry
gpt-oss lands in Azure and Windows AI Foundry

Microsoft has launched OpenAI’s new open-weight AI models, gpt-oss-120b and gpt-oss-20b, through its Azure and Windows AI Foundry platforms. These models are fully open and customizable, giving developers deep control over how and where they deploy them.
The bigger one, gpt-oss-120b, comes with 120 billion parameters. It comes close to o4-mini performance but stays efficient enough for single-GPU servers. The smaller gpt-oss-20b is even more flexible. It’s designed to run on local Windows machines with a decent discrete GPU, ideal for offline apps and fast-response tasks.
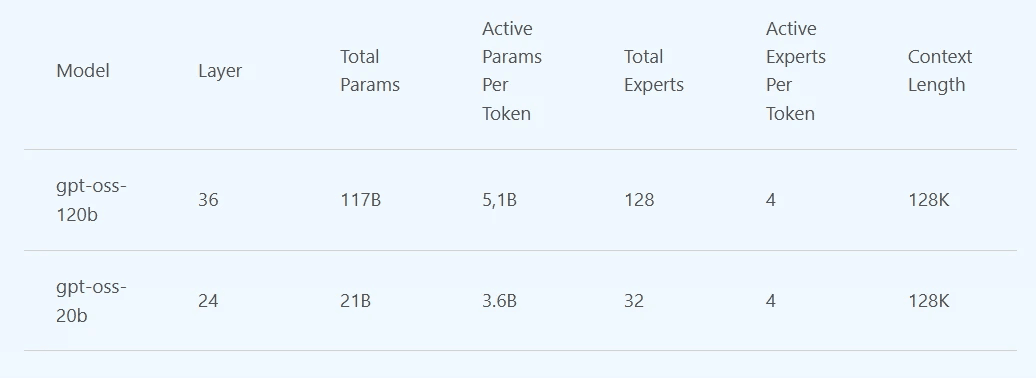
This is the first time since GPT-2 that OpenAI has released open weights. It means no vendor lock-in; you can run these models locally, in your datacenter, or across the cloud.
Foundry makes the experience even more customizable. Developers can fine-tune models using LoRA, QLoRA, or PEFT. You can compress them, quantize for performance, edit attention layers, or integrate them into ONNX and Kubernetes stacks. There’s even an offline deployment option with Foundry Local.

Microsoft says this is AI becoming part of the stack, not just an extra tool. “With gpt-oss, you can build with confidence and customize without compromise,” said Microsoft AI execs Asha Sharma and Logan Iyer.
It also gives Microsoft a serious edge in hybrid AI. Big models now work across cloud and edge, unlocking faster, cheaper, and more private use cases. It’s worth noting that the support is live on Windows and Azure, with support for Mac coming later down the line.
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more


Improve this guide




User forum
0 messages