OpenAI Releases GPT‑5.3‑Codex‑Spark for Real-Time Coding

OpenAI today unveiled a research preview of GPT‑5.3‑Codex‑Spark, a smaller, speed-optimized version of GPT‑5.3‑Codex designed for real-time coding. This comes just a few days after the company unveiled the GPT-5.3-Codex to take on Anthropic’s Claude Opus 4.6.
Notably, the release of GPT‑5.3‑Codex‑Spark marks the first milestone in OpenAI’s collaboration with Cerebras, which aims to deliver coding results almost instantly on ultra-low latency hardware. Codex-Spark can produce more than 1000 tokens per second while remaining capable of real-world development tasks.
Codex-Spark optimized for speed and interactivity
Unlike previous Codex models, Codex-Spark focuses on interactive coding. It’s designed to make specific edits, refine logic, and update interfaces in real time. The model has a 128k token context window and currently supports text-only interactions. Users can collaborate, interrupt, and redirect their work instantly, making it suitable for rapid iteration and hands-on coding experiments.
Early benchmarks show Codex-Spark completing tasks far faster than its predecessor while maintaining strong accuracy. On SWE-Bench Pro and Terminal-Bench 2.0, the model reduced task durations significantly, confirming that speed improvements are not just token-level but across the full request-response pipeline. OpenAI also introduced WebSocket-based persistent connections, cutting per-token overhead by 30% and time-to-first-token by 50%.
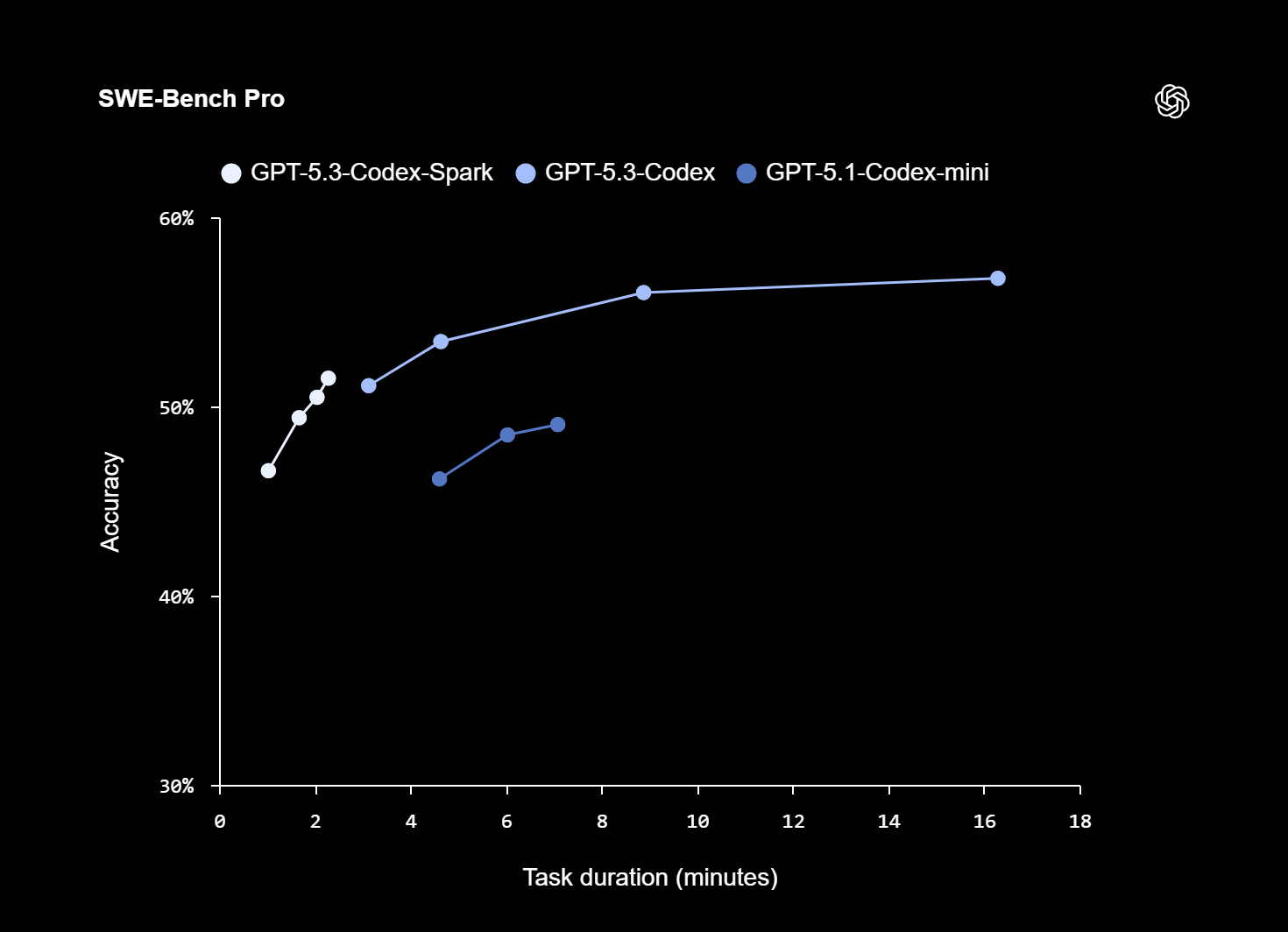
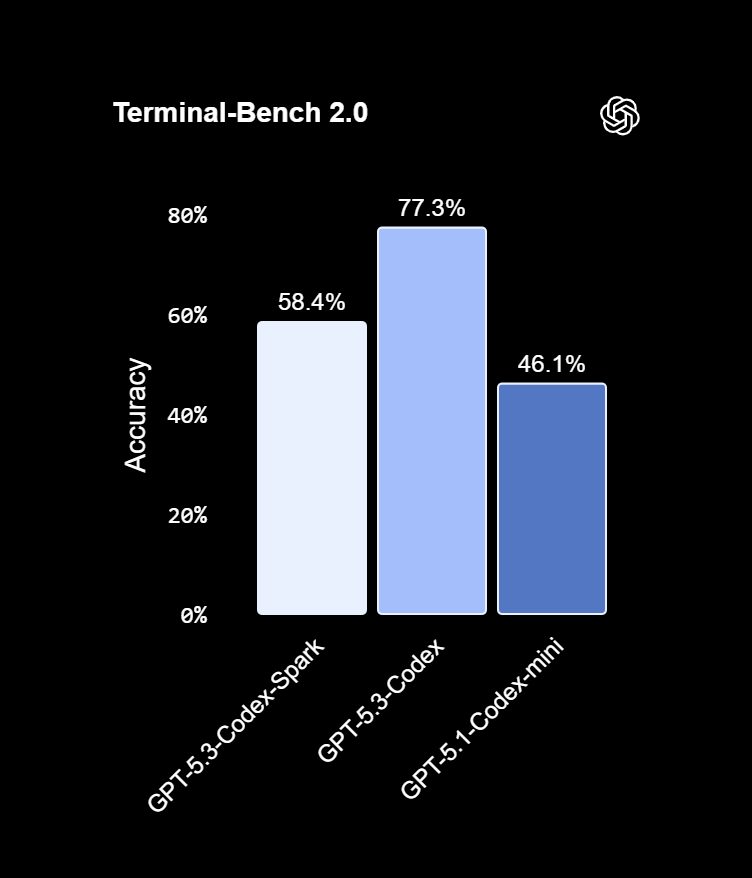
Powered by Cerebras, Complementing GPU Infrastructure
Codex-Spark runs on Cerebras’ Wafer Scale Engine 3, a purpose-built AI chip for ultra-low latency inference. GPUs remain central for training and broad usage, while Cerebras handles workflows where minimal lag matters most. Sean Lie, Cerebras CTO, emphasized the model’s potential to reshape developer workflows, introducing new interaction patterns and use cases.
Available now as a research preview for ChatGPT Pro users, Codex-Spark comes with separate rate limits during the preview. Moreover, OpenAI plans to expand access gradually and integrate user feedback to refine the model’s real-time capabilities, while keeping safety safeguards in place.
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more


Improve this guide


User forum
0 messages