Gemini 3.1 Flash-Lite Launches as Google’s Fastest & Most Cost-Efficient Gemini 3 Model Yet

Google has just announced Gemini 3.1 Flash-Lite, which the company says is the fastest and most cost-efficient model in the Gemini 3 series so far. Starting today, Gemini 3.1 Flash-Lite is rolling out in preview to developers through Google AI Studio via the Gemini API. Enterprise customers can also access it through Vertex AI.
A cost-efficient model designed for heavy developers demand
At $0.25 per million input tokens and $1.50 per million output tokens, Google has positioned Gemini 3.1 Flash-Lite as a scale-first model. The company further adds that it outperforms Gemini 2.5 Flash with a 2.5x faster time to first token and offers 45% faster output speed, based on Artificial Analysis benchmarks.
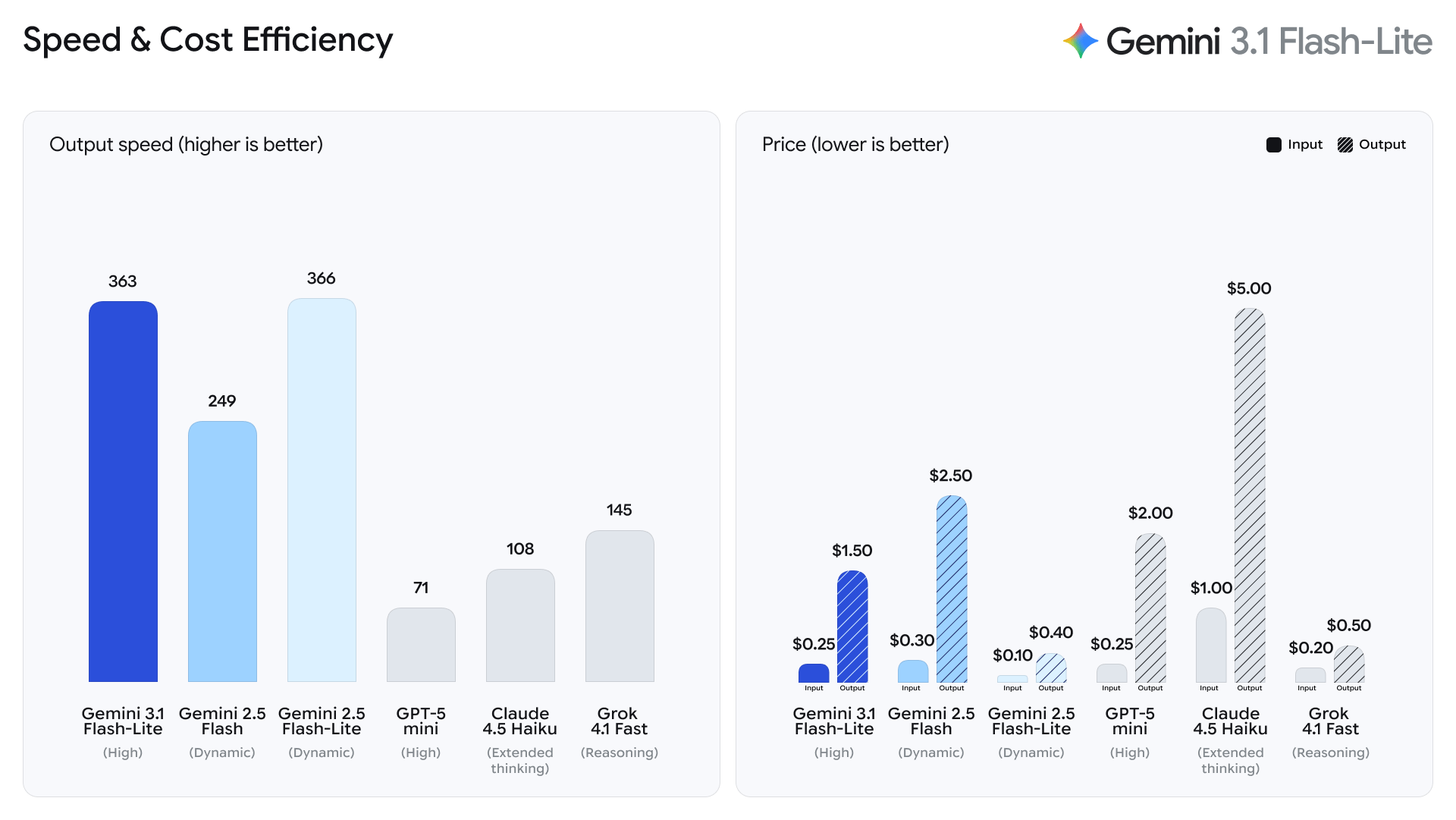
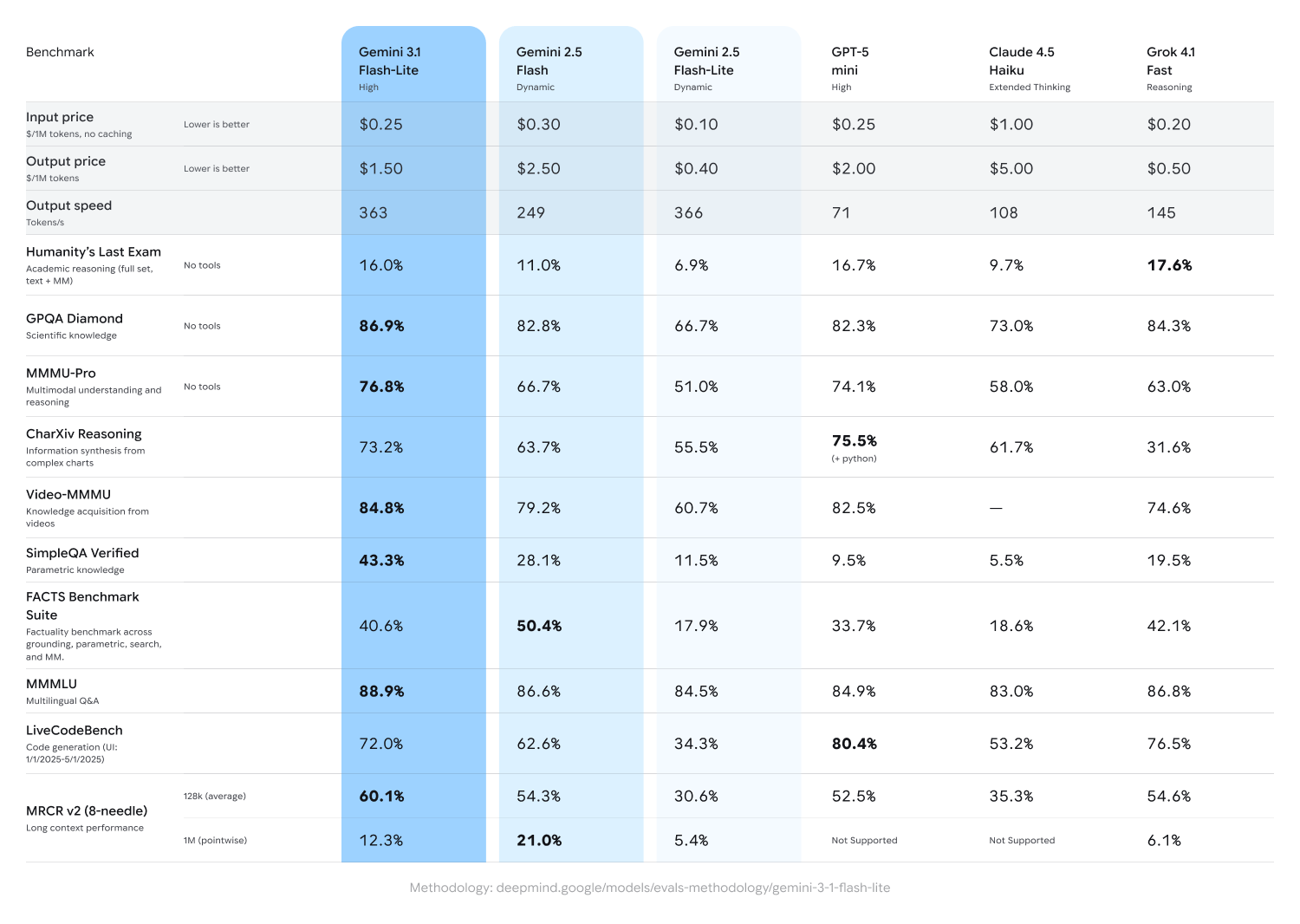
Gemini 3.1 Flash-Lite is designed for developers building real-time experiences. Think of high-frequency translation, content moderation, and large-scale automation tasks where cost and latency matter just as much as intelligence. Well, Flash-Lite doesn’t seem to compromise much on quality. It scored 1432 on the Arena.ai leaderboard and posted strong benchmark numbers, including 86.9% on GPQA Diamond and 76.8% on MMMU Pro. Google claims it even surpasses advanced Gemini models from earlier generations in some areas.
Adaptive intelligence without the hefty price tag
Besides raw speed, Gemini 3.1 Flash-Lite includes adjustable “thinking levels” inside AI Studio and Vertex AI. Developers can choose how much reasoning the model applies to a task, helping manage cost while scaling performance. Early testers, including companies like Latitude and Cartwheel, say the model handles complex inputs with precision while maintaining instruction accuracy. Speaking of AI models, let’s not forget that Microsoft today also added OpenAI’s latest GPT-5.3 Instant model to Copilot Chat and Copilot Studio.
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more


Improve this guide



User forum
0 messages