TPU vs GPU: What is better? [Performance & Speed Comparison]
Key notes
- Tensor Processing Units are specialized integrated circuits (ICs) for specific applications useful in accelerating ML workloads.
- While NVIDIA focuses efforts on GPUs, google has pioneered TPU technology and is the leader in this department.
- TPUs, allow for a much-reduced training cost that outweighs the initial, additional programming expenses.

In this article, we will be making a TPU vs. GPU comparison. But before we delve into it, here is what you must know.
Machine Learning and AI tech have accelerated the growth of intelligent apps. To this end, semiconductor firms are continually creating accelerators and processors, including TPU and CPU, to deal with more complex apps.
Some users have had issues understanding when it is recommended to use a TPU and when to use a GPU for their computer tasks.
A GPU, also known as a Graphical Processing Unit, is your PC’s video card to offer you a visual and immersive PC experience. For example, you could follow easy steps if your PC is not detecting the GPU.
To better understand these circumstances, we will also need to clarify what a TPU is and how it compares to a GPU.
What is a TPU?
TPUs or Tensor Processing Units are specialized integrated circuits (ICs) for specific applications, also known as ASICs (application-specific integrated circuits). Google created TPUs from scratch, beginning to use them in 2015, and opened them to the public in 2018.

TPUs are offered as minor chip or cloud versions. To speed machine learning for a neural network using the TensorFlow software, cloud TPUs solve complicated matrix and vector operations at incredible speeds.
With TensorFlow, the Google Brain Team-developed an open-source machine learning platform, researchers, devs, and enterprises can construct and operate AI models using Cloud TPU hardware.
When training complex and robust neural network models, TPUs reduce the time to accuracy value. This means that deep learning models that may have taken weeks to train using GPUs take less than a fraction of that time.
Is TPU the same as GPU?
They are architecturally highly distinct. A Graphical Processing Unit is a processor in and of itself, albeit one that is piped toward vectorized numerical programming. GPUs are, in effect, the next generation of the Cray supercomputers.
TPUs are coprocessors that don’t execute instructions by themself; the code is executed on CPUs, which feeds the TPU a flow of small operations.
When should I use TPU?
TPUs in the cloud are tailored to particular applications. You may prefer to execute your machine learning tasks using GPUs or CPUs in some instances. In general, the following principles may help you evaluate if TPU is the best option for your workload:
- Matrix computations are dominant in the models
- Within the model’s main training loop, there are no custom TensorFlow operations
- They’re models that go through weeks or months of training
- They are massive models that have extensive, effective batch sizes.
Now let’s jump into some direct TPU vs. GPU comparison.
What are the differences between GPU and TPU?
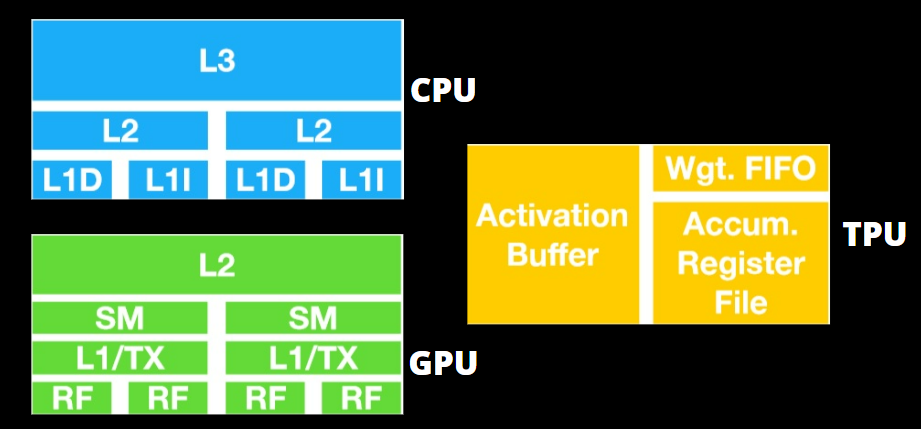
TPU vs. GPU architecture
The TPU isn’t highly complex hardware and feels like a signal processing engine for radar applications and not the traditional X86-derived architecture.
Despite having many matrix multiplication divisions, it’s less of a GPU and more of a coprocessor; it merely executes the commands received given by a host.
Because there are so many weights to input to the matrix multiplication component, the TPU’s DRAM is operated as a single unit in parallel.
Additionally, because TPUs can only conduct matrix operations, TPU boards are linked to CPU-based host systems to accomplish tasks that the TPUs can’t handle.
The host computers are in charge of delivering data to the TPU, preprocessing, and fetching details from Cloud Storage.
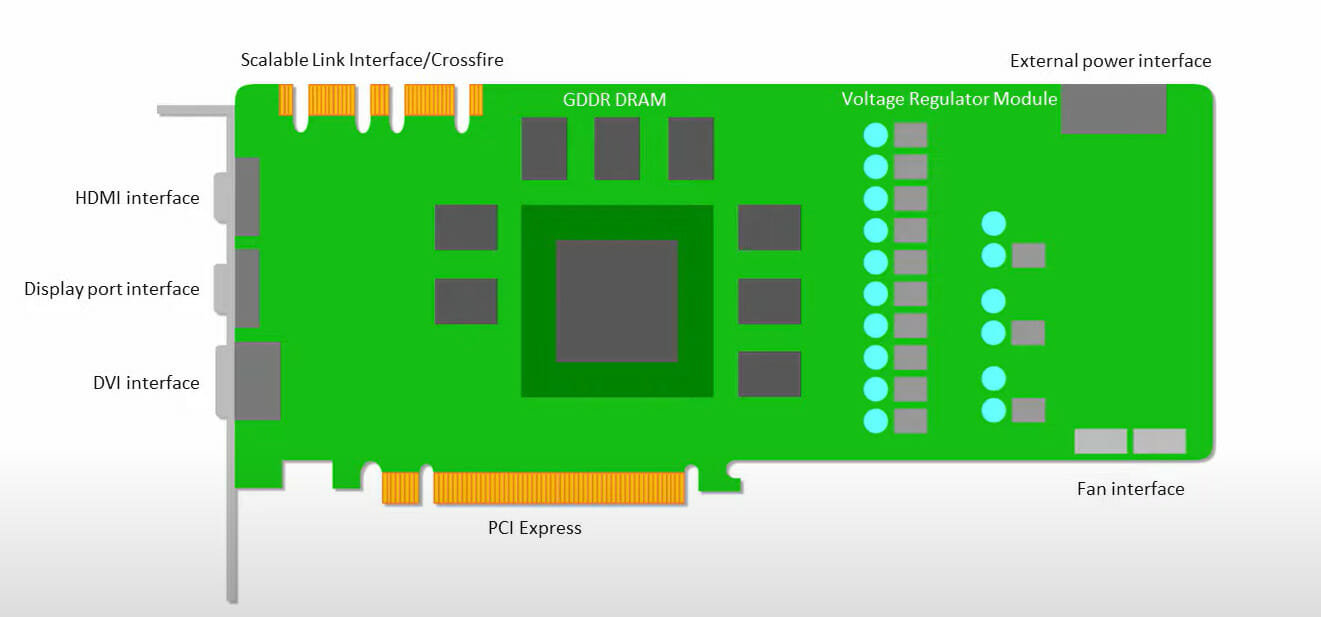
GPUs are more concerned with applying available cores to work than accessing the low-latency cache.
Many PCs (Processor Clusters) with multiple SMs (Streaming Multiprocessors) become a single GPU gadget, with layer one instruction cache layers and accompanying cores housed in every SM.
Before data extraction from global GDDR-5 memory, one SM typically utilizes a shared layer of two caches and a dedicated layer of one cache. The GPU architecture is memory latency tolerant.
A GPU operates with a minimal number of memory cache levels. However, because a GPU features more transistors devoted to processing, it is less concerned with its time to access data in the memory.
The possible memory access delay is hidden as the GPU is kept occupied with adequate calculations.
TPU vs. GPU speed
This original TPU generation targeted inference, which uses a learned model rather than a trained one.
The TPU is 15 to 30 times faster than current GPUs and CPUs on commercial AI applications that use neural network inference.
Furthermore, the TPU is significantly energy-efficient, with between a 30 to 80-fold increase in TOPS/Watt value.
Hence in making a TPU vs. GPU speed comparison, the odds a skewed towards the Tensor Processing Unit.
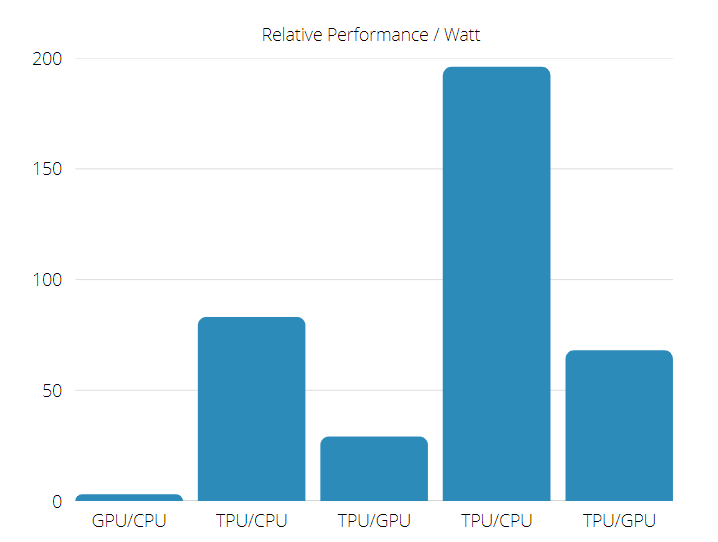
TPU vs. GPU performance
A TPU is a tensor processing machine created to speed up Tensorflow graph computations.
On a single board, each TPU may provide as much as 64 GB of high-bandwidth memory and 180 teraflops of floating-point performance.
A comparison between Nvidia GPUs and TPUs is shown below. The Y-axis depicts the number of photos per second, while the X-axis represents the various models.
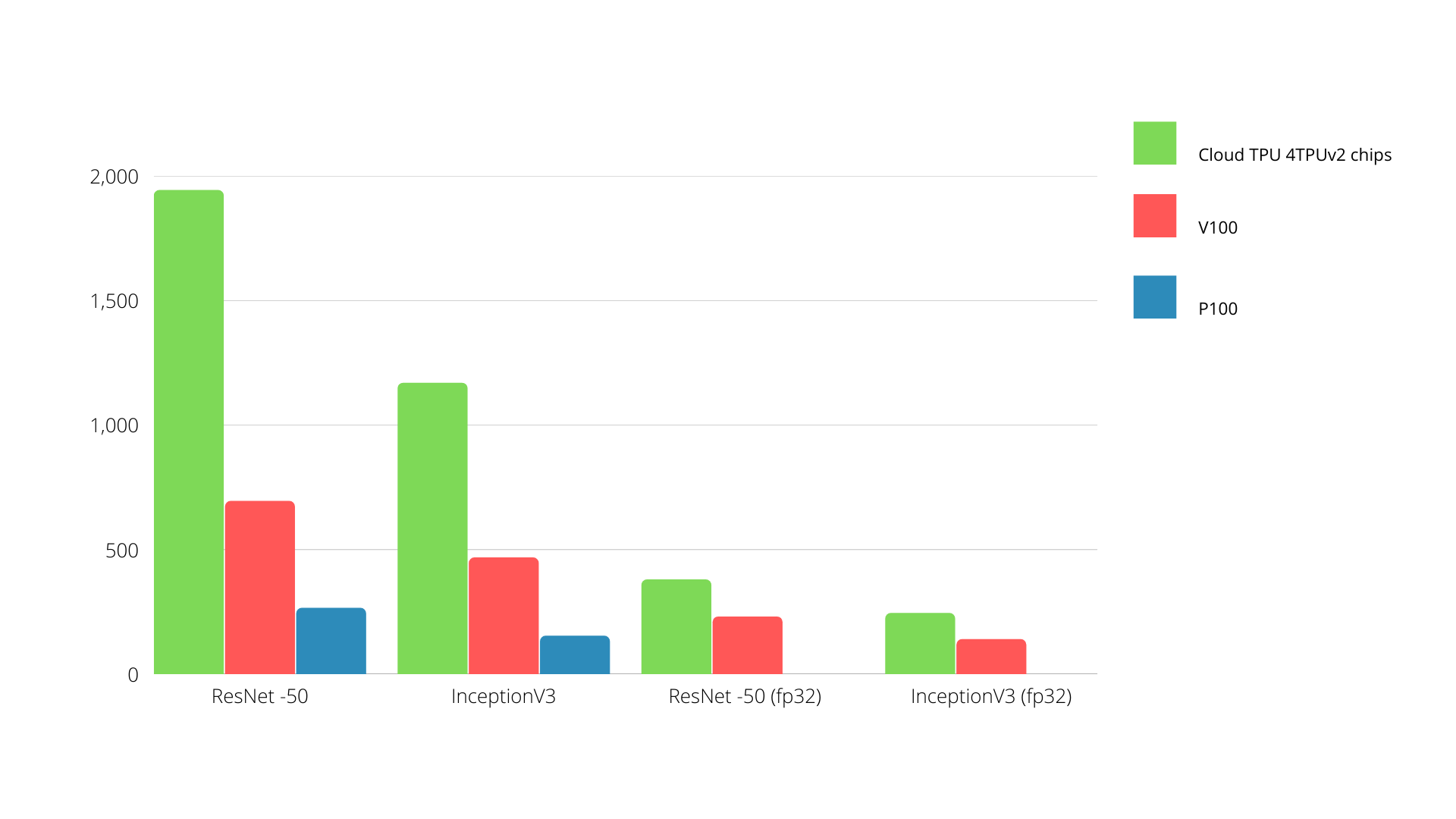
TPU vs. GPU machine learning
Below are the training times for CPUs and GPUs using different batch sizes and iterations per Epoch:
- Iterations/epoch: 100, Batch size: 1000, Total epochs: 25, Parameters: 1.84 M, and Model type: Keras Mobilenet V1 (alpha 0.75).
| ACCELERATOR | GPU (NVIDIA K80) | TPU |
| Training Accuracy (%) | 96.5 | 94.1 |
| Validation Accuracy (%) | 65.1 | 68.6 |
| Time Per Iteration (ms) | 69 | 173 |
| Time Per Epoch (s) | 69 | 173 |
| Total Time (minutes) | 30 | 72 |
- Iterations/epoch: 1000, Batch size: 100, Total epochs: 25, Parameters: 1.84 M, and Model type: Keras Mobilenet V1 (alpha 0.75)
| ACCELERATOR | GPU (NVIDIA K80) | TPU |
| Training Accuracy (%) | 97.4 | 96.9 |
| Validation Accuracy (%) | 45.2 | 45.3 |
| Time Per Iteration (ms) | 185 | 252 |
| Time Per Epoch (s) | 18 | 25 |
| Total Time (minutes) | 16 | 21 |
With a smaller batch size, the TPU takes much longer to train, as seen from the training time. However, TPU performance is closer to the GPU with increased batch size.
Hence in making a TPU vs. GPU training comparison, a lot has to do with epochs and batch size.
TPU vs. GPU benchmark
With 0.5 watts/TOPS, a single Edge TPU can execute four trillion operations/per second. Several variables influence how well this translates to app performance.
Neural network models have distinct requirements, and overall output varies depending on the host USB speed, CPU, and other system resources of the USB accelerator device.
With that in mind, the graphic below contrasts time spent making single inferences on an Edge TPU with various standard models. Of course, all models running are the TensorFlow Lite versions for comparison’s sake.
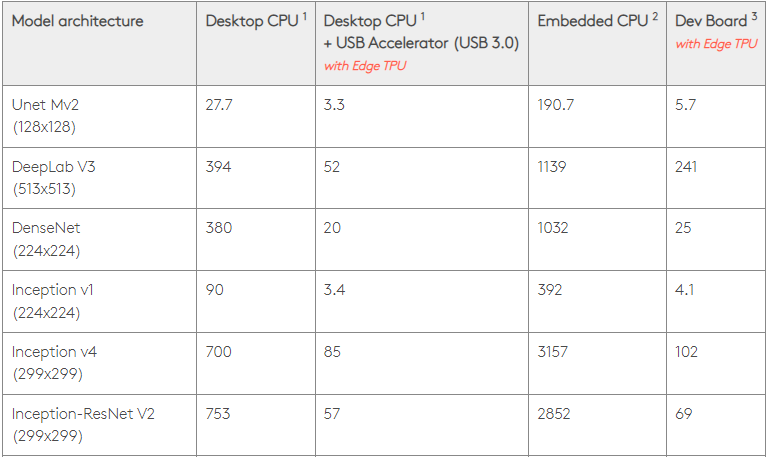
Please note that the given data above show the time it takes to run the model. However, it excludes the time it takes to process the input data, which varies by application and system.
The results of GPU benchmarks are compared to the user’s desired gameplay quality settings and resolution.
Based on evaluating upwards of 70,000 benchmark tests, sophisticated algorithms have been meticulously constructed to generate 90 percent reliable estimations of gaming performance.
Although the performance of graphics cards varies widely across games, this comparison image below gives a broad rating index for some graphics cards.
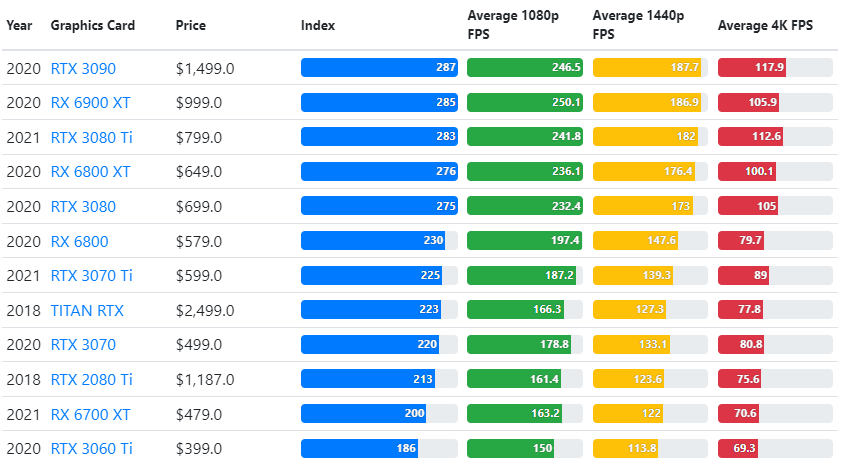
TPU vs. GPU price
They have a significant price difference. TPUs are five times more costly than GPUs. Here are some examples:
- An Nvidia Tesla P100 GPU costs $1.46 per hour
- Google TPU v3 costs $8.00 per hour
- TPUv2 with GCP on-demand access $4.50 per hour
If optimizing for cost is the aim, you should go for a TPU only if it trains a model 5X the speed of a GPU.
What is the difference between CPU vs. GPU vs. TPU?
The distinction between the TPU, GPU, and CPU is that the CPU is a non-specific purposed processor that handles all of the computer’s computations, logic, input, and output.
On the other hand, GPU is an extra processor used to improve the Graphical Interface (GI) and do high-end activities. TPUs are strong, specially made processors used to execute projects developed using a particular framework, such as TensorFlow.
We categorize them as follows:
- Central Processing Unit (CPU) – Control all aspects of a computer
- Graphics Processing Unit (GPU) – Improve the computer’s graphics performance
- Tensor Processing Unit (TPU) – ASIC explicitly designed for TensorFlow projects
Does Nvidia make TPU?
Many people have wondered how NVIDIA would react to Google’s TPU, but we now have answers.
Rather than being concerned, NVIDIA has successfully de-positioned TPU as a tool it can utilize when it makes sense but still keeping its CUDA software and GPUs in the lead.
It keeps a control point for IoT machine learning adoption by making the tech open source. However, the danger with this method is that it may provide credence to a concept that might become a challenge to the long-term aspirations of data center inference engines for NVIDIA.
Is GPU or TPU better?
In conclusion, we must say that although developing the algorithms to enable the effective use of a TPU costs a bit extra, the reduced training costs generally outweigh the additional programming expenses.
Other reasons to choose a TPU include the fact that the v3-128 8’s G of VRAM surpasses that of Nvidia GPUs, making the v3-8 a better alternative for processing large datasets associated with NLU and NLP.
Higher speeds may also lead to quicker Iteration during dev cycles, leading to faster and more frequent innovation, increasing the likelihood of success in the market.
The TPU outperforms the GPU in terms of speed of innovation, easiness to use, and affordability; consumers and cloud architects should consider the TPU in their ML and AI initiatives.
The TPU from Google has plenty of processing capacity, and the user must coordinate data input to make sure there is no overloading.
There you have it, a total TPU vs. GPU comparison. We would love to know your thoughts and see if you have done any tests and what results in you received on TPU and GPU.
Remember, you can enjoy an immersive PC experience using any of the best graphics cards for Windows 11.
Read our disclosure page to find out how can you help Windows Report sustain the editorial team. Read more


Improve this guide




User forum
0 messages